This article uses a simple 2-2-1 neural network example to show one full lifecycle of parameter updates. If you want to expand any step further, a language model or a textbook companion can help unpack the details.
Setup
Task
Input: $x \in \mathbb{R}^2$
Output: $\hat{y} \in \mathbb{R}$
Structure
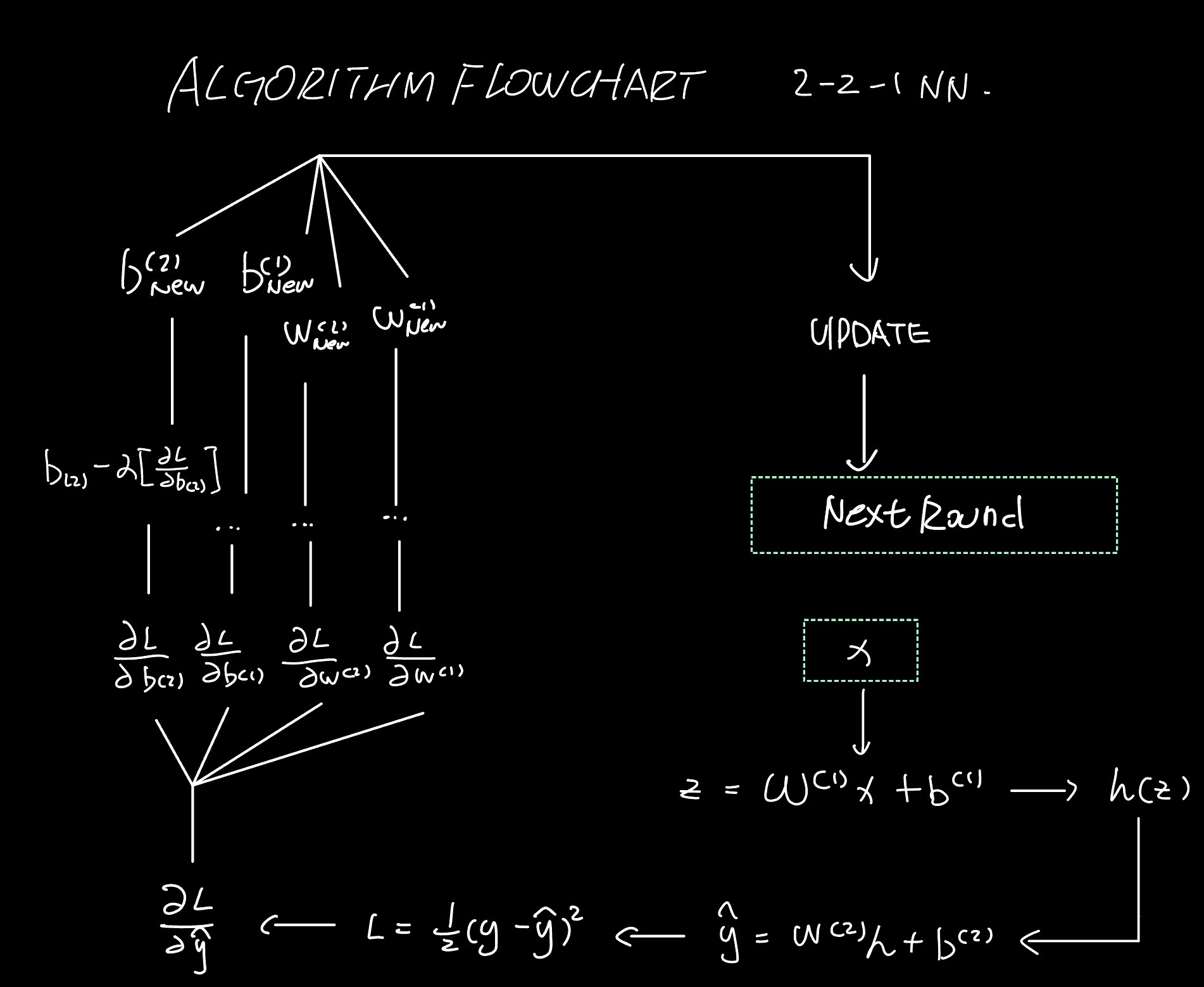
$$ \begin{aligned} h &= \operatorname{ReLU}(W^{(1)}x + b^{(1)}) \\ \hat{y} &= W^{(2)}h + b^{(2)} \end{aligned} $$Parameter dimensionality
$$ \begin{aligned} W^{(1)} &\in \mathbb{R}^{2 \times 2}, \quad b^{(1)} \in \mathbb{R}^2 \\ W^{(2)} &\in \mathbb{R}^{1 \times 2}, \quad b^{(2)} \in \mathbb{R} \end{aligned} $$Loss function
$$ L = \frac{1}{2}(\hat{y} - y)^2 $$Phase 0: Initialization
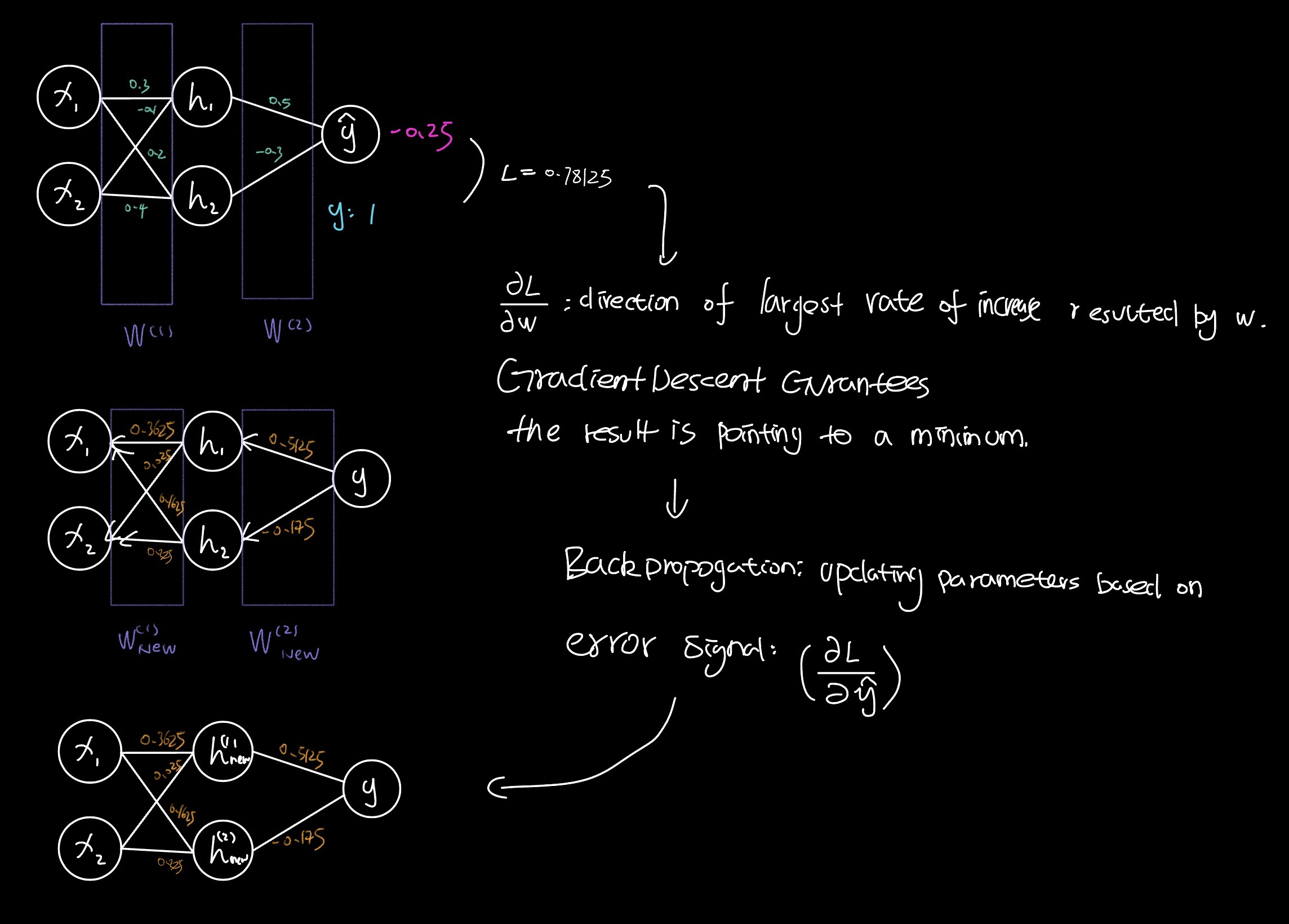
$$ \begin{aligned} W^{(1)} &= \begin{bmatrix} 0.3 & -0.1 \\ 0.2 & 0.4 \end{bmatrix}, \quad b^{(1)} = \begin{bmatrix} 0 \\ 0 \end{bmatrix} \\ W^{(2)} &= \begin{pmatrix} 0.5 & -0.3 \end{pmatrix}, \quad b^{(2)} = 0 \end{aligned} $$Phase 1: Forward Pass
Input:
$$ x = \begin{pmatrix} 1 \\ 2 \end{pmatrix}, \quad y = 1 $$1. Pre-activation
$$ z^{(1)} = W^{(1)}x + b^{(1)} = \begin{pmatrix} 0.3 & -0.1 \\ 0.2 & 0.4 \end{pmatrix}\begin{pmatrix} 1 \\ 2 \end{pmatrix} = \begin{pmatrix} 0.1 \\ 1.0 \end{pmatrix} $$2. Activation
$$ h = \operatorname{ReLU}(z^{(1)}) = \begin{pmatrix} \max(0, 0.1) \\ \max(0, 1.0) \end{pmatrix} = \begin{pmatrix} 0.1 \\ 1.0 \end{pmatrix} $$3. Output
$$ \hat{y} = W^{(2)}h + b^{(2)} = \begin{pmatrix} 0.5 & -0.3 \end{pmatrix}\begin{pmatrix} 0.1 \\ 1.0 \end{pmatrix} = 0.05 - 0.3 = -0.25 $$4. Loss
$$ L = \frac{1}{2}(\hat{y} - y)^2 = \frac{1}{2}(-0.25 - 1)^2 = \frac{1}{2}(-1.25)^2 = 0.78125 $$Phase 2: Backpropagation
1. Output error signal
$$ \frac{\partial L}{\partial \hat{y}} = \hat{y} - y = -1.25 $$2. Gradients for the output layer
$$ \begin{aligned} \frac{\partial L}{\partial W^{(2)}} &= \frac{\partial L}{\partial \hat{y}} h^\top = -1.25 \begin{pmatrix} 0.1 & 1.0 \end{pmatrix} = \begin{pmatrix} -0.125 & -1.25 \end{pmatrix} \\ \frac{\partial L}{\partial b^{(2)}} &= \frac{\partial L}{\partial \hat{y}} \cdot \frac{\partial \hat{y}}{\partial b^{(2)}} = (\hat{y} - y)(1) = -1.25 \end{aligned} $$3. Error signal for the hidden layer
$$ \frac{\partial L}{\partial h} = \left(W^{(2)}\right)^\top \frac{\partial L}{\partial \hat{y}} = \begin{pmatrix} 0.5 \\ -0.3 \end{pmatrix}(-1.25) = \begin{pmatrix} -0.625 \\ 0.375 \end{pmatrix} $$4. Pass through ReLU
Since
$$ z^{(1)} = \begin{pmatrix} 0.1 \\ 1.0 \end{pmatrix} $$both entries are positive, so
$$ \operatorname{ReLU}'(z^{(1)}) = \begin{bmatrix} 1 \\ 1 \end{bmatrix} $$and therefore
$$ \frac{\partial L}{\partial z^{(1)}} = \frac{\partial L}{\partial h} \odot \operatorname{ReLU}'(z^{(1)}) = \begin{bmatrix} -0.625 \\ 0.375 \end{bmatrix} $$5. Gradients for the first layer
$$ \begin{aligned} \frac{\partial L}{\partial W^{(1)}} &= \frac{\partial L}{\partial z^{(1)}} x^\top = \begin{pmatrix} -0.625 \\ 0.375 \end{pmatrix}\begin{pmatrix} 1 & 2 \end{pmatrix} = \begin{pmatrix} -0.625 & -1.25 \\ 0.375 & 0.75 \end{pmatrix} \\ \frac{\partial L}{\partial b^{(1)}} &= \frac{\partial L}{\partial z^{(1)}} = \begin{bmatrix} -0.625 \\ 0.375 \end{bmatrix} \end{aligned} $$Phase 3: Parameter Update
Using gradient descent,
$$ \theta_{\text{new}} = \theta_{\text{old}} - \alpha \nabla_\theta L $$Take $\alpha = 0.1$.
Updated second layer
$$ \begin{aligned} W^{(2)}_{\text{new}} &= W^{(2)} - \alpha \frac{\partial L}{\partial W^{(2)}} = \begin{pmatrix} 0.5 & -0.3 \end{pmatrix} - 0.1 \begin{pmatrix} -0.125 & -1.25 \end{pmatrix} = \begin{pmatrix} 0.5125 & -0.175 \end{pmatrix} \\ b^{(2)}_{\text{new}} &= b^{(2)} - \alpha \frac{\partial L}{\partial b^{(2)}} = 0 - 0.1(-1.25) = 0.125 \end{aligned} $$Updated first layer
$$ \begin{aligned} W^{(1)}_{\text{new}} &= W^{(1)} - \alpha \frac{\partial L}{\partial W^{(1)}} = \begin{pmatrix} 0.3 & -0.1 \\ 0.2 & 0.4 \end{pmatrix} - 0.1 \begin{pmatrix} -0.625 & -1.25 \\ 0.375 & 0.75 \end{pmatrix} = \begin{pmatrix} 0.3625 & 0.025 \\ 0.1625 & 0.325 \end{pmatrix} \\ b^{(1)}_{\text{new}} &= b^{(1)} - \alpha \frac{\partial L}{\partial b^{(1)}} = \begin{bmatrix} 0 \\ 0 \end{bmatrix} - 0.1 \begin{bmatrix} -0.625 \\ 0.375 \end{bmatrix} = \begin{bmatrix} 0.0625 \\ -0.0375 \end{bmatrix} \end{aligned} $$Flowcharts
Handwritten Form
